

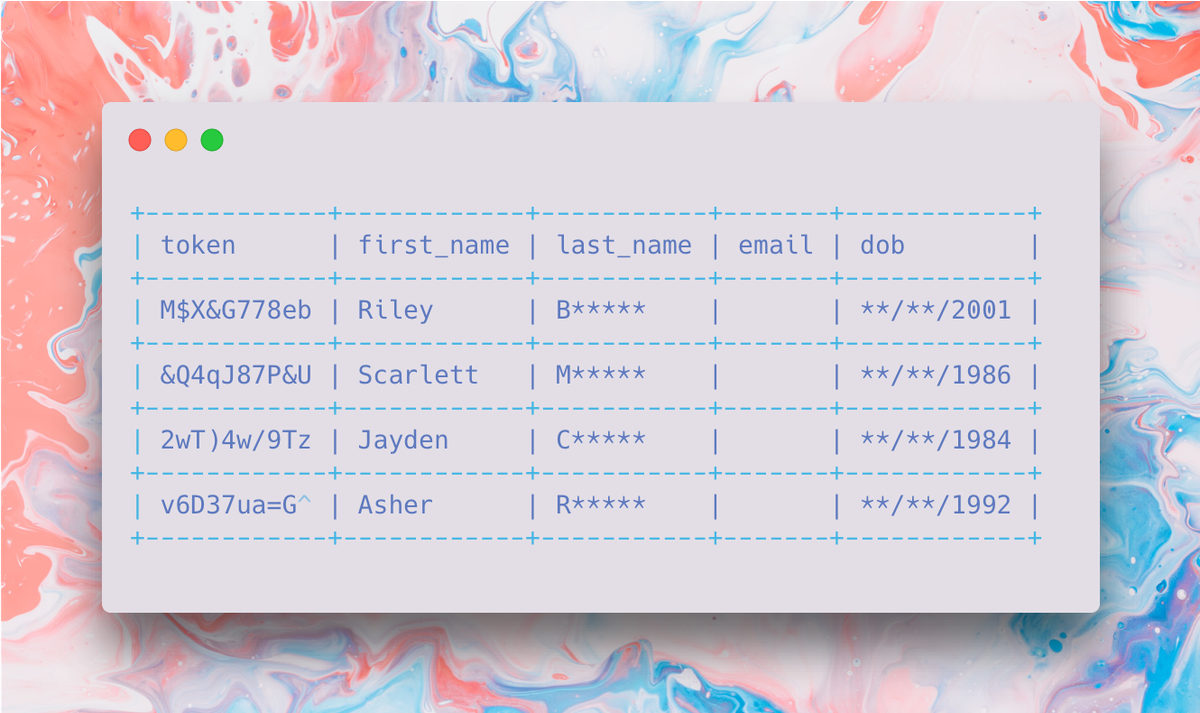
Storing customer information that contains personal data is essential to nearly every modern business. Regardless of the sector, it's highly likely you will be dealing with some form of sensitive dater, whether healthcare information (PHI), payment card information (PCI) or other personally identifiable information (PII).
The Problem
Over the last decade, there has been a move to decentralise data, applications and services across multiple databased, locations and environments. While decentralisation has enabled greater flexibility and convenience, the increased data footprint and duplication of data storage has made traditional data security strategies less effective, making it much harder to implement and monitor good data governance policies.
Sensitive data is a valuable asset to businesses, who often rely on this information for critical operations. Hindering the ability for staff and services to access this information can limit people's ability to perform their job, make informed decisions, slow down processes and create bottlenecks in business workflows. It is essential to have a balance between security and accessibility to ensure that staff and services can access the data they need to preform critical workflows while meeting compliance obligations, protecting sensitive customer information, and maintaining overall security.
Solution
Data vaulting is a concept that has been around in the payment card industry for many years now. The Payment Card Industry Data Security Standard (PCI DSS) was developed to govern the safe storage of sensitive credit card details and has been a very effective way to limit fraud and misuse of credit and debit card information.
In recent years there has been a move to utilise the same data vaulting strategy to protect other forms of sensitive information like PHI and PII data. Unlike the payment card industry, there is not a current consistent standard for PII data vaulting. Still, we can start to identify several critical components that should be part of any standard as it develops.
Centralise & Isolate
Data sprawl occurs when sensitive data, like names, emails, passport details or health records, are replicated from one system to another, increasing the amount of infrastructure that requires monitoring and access oversite, increasing regulatory compliance burden and increasing the attack surface area for malicious hackers to exploit.
Identifying sensitive data and centralising it in a secure and isolated location makes monitoring and controlling access much more straightforward as the data is isolated in a single controlled space rather than replicated across your infrastructure and systems.
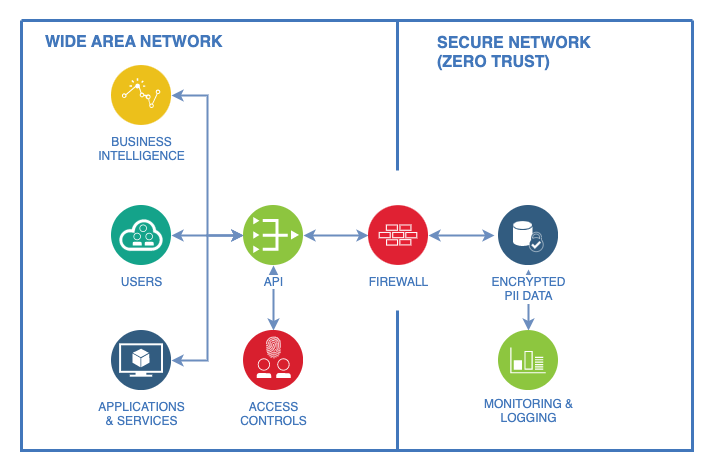
A token can be used to maintain a reference to the centralised data from external systems, limiting the need for replication and ensuring access to the data is still available when required. The sensitive PII data is isolated on a network with the highest level of network security, and access can be granted by a single controlled interface such as an API.
Isolating PII data from other data sources, systems, and services allows you to have greater control over the geographical location PII data is stored and accessed, making compliance with local laws and regulations like the Australian Privacy Act 1988, General Data Protection Regulation (GDPR) or California Consumer Privacy Act (CCPA) much more straightforward as PII data can be stored in a location separate to the users and services accessing it, and in addition to access levels, geographical controls can be added to restrict data access from particular areas.
Encrypt Data At Rest
It's essential to assume that any network and system security cannot be fully trusted and that unauthorised system access is possible. If there is unauthorised access, unencrypted data is vulnerable.
Encrypting data at rest is an essential aspect of a comprehensive data security strategy, as it helps to protect sensitive information in the event that systems are breached and accessed. By encrypting data at rest, the raw data is protected even if the secure network itself is compromised.
Limit Access
Managing sensitive data means having control over what type of data you protect, who has access, where they are accessing from and how that data is displayed.
By limiting access to sensitive data to only those who need it, the risk of data breaches or unauthorised access is reduced. By controlling how data is displayed to different users or authorised services, you can further limit the level of exposure whilst allowing business process and workflows to be completed without exposing unnecessary detail.
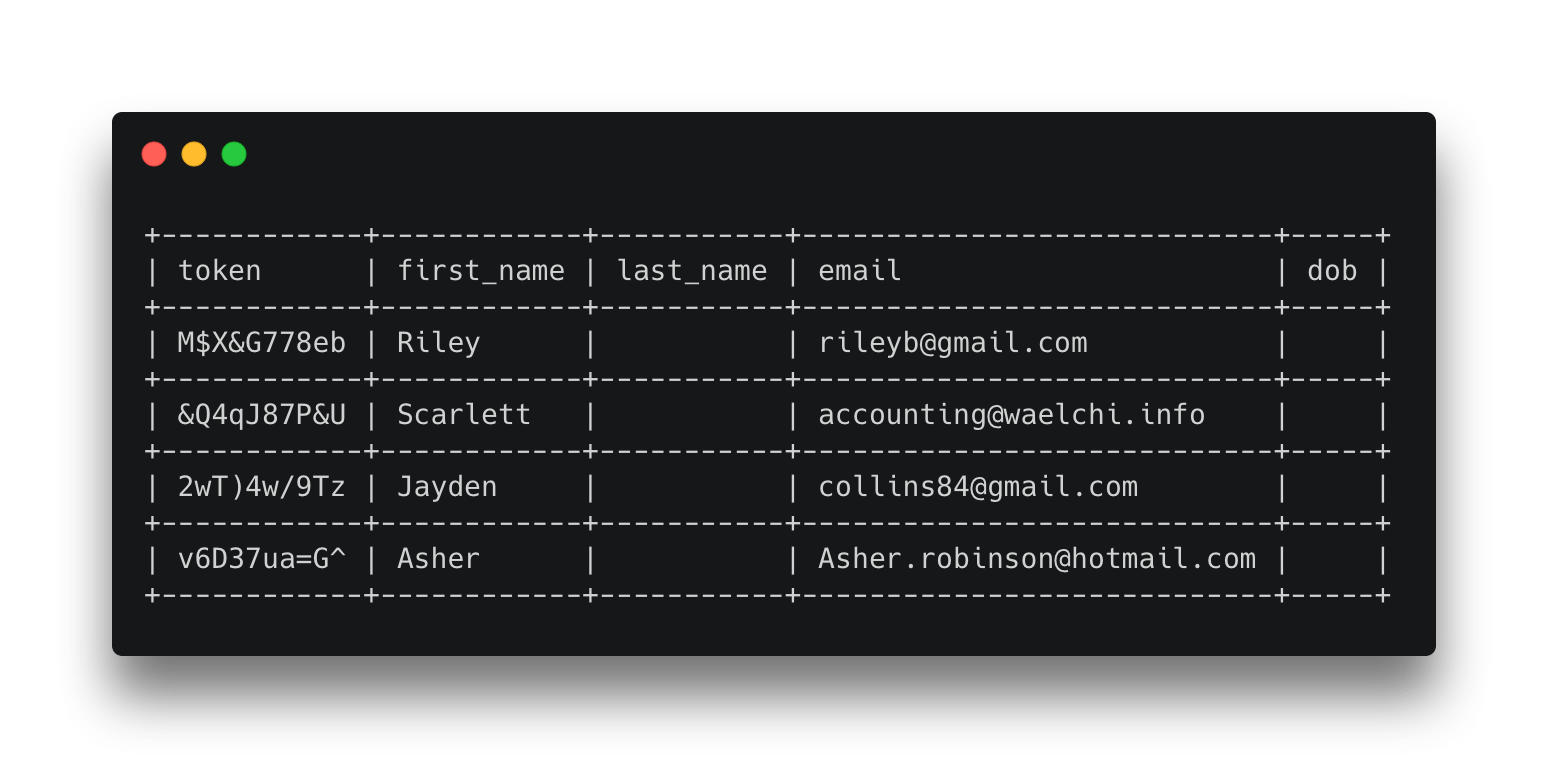
Suppose we hold the following personal information about customers: first_name, last_name, email, and date of birth (dob).
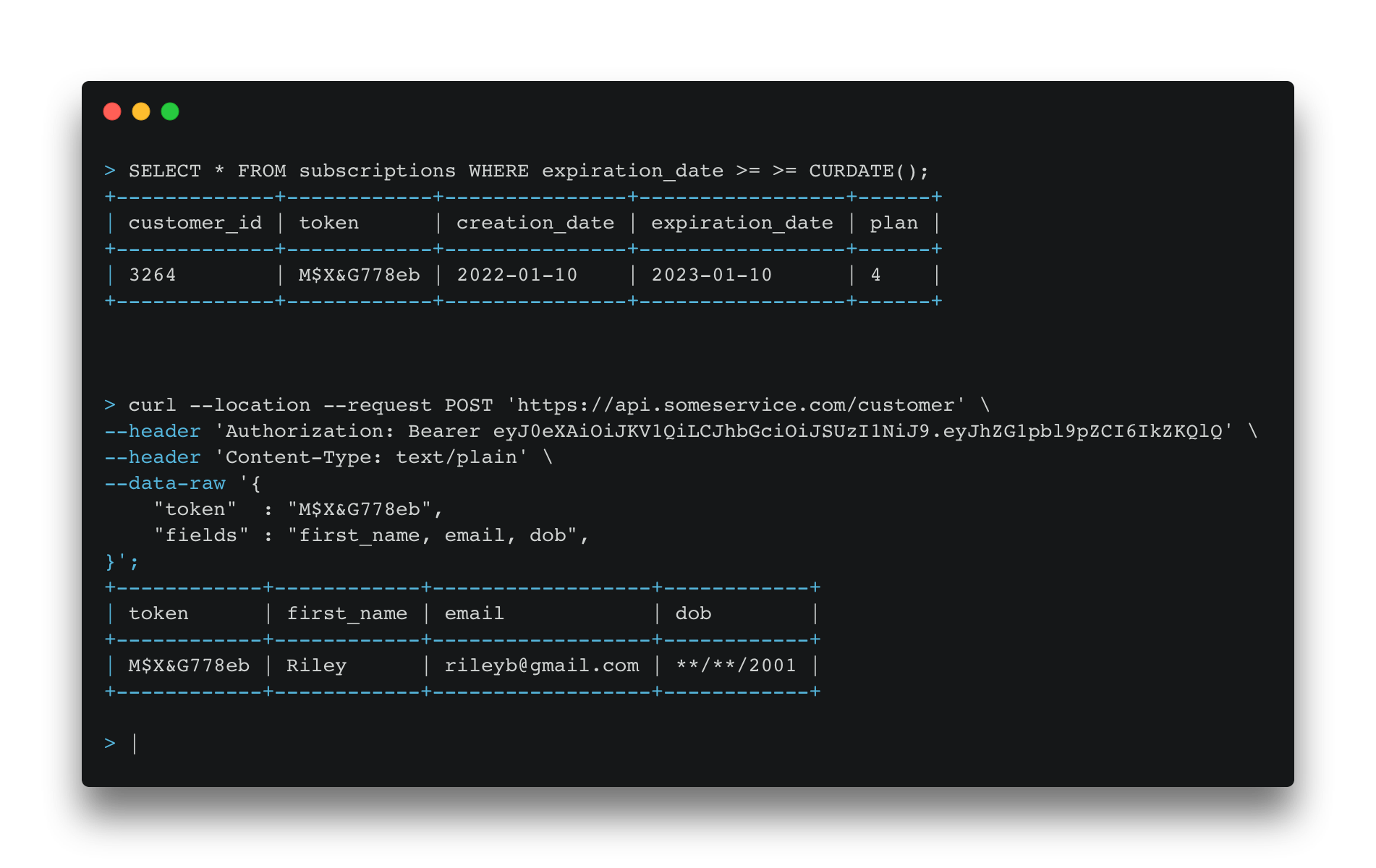
Now we want our marketing service that utilises our business intelligence (BI) data to send targeted emails to customers. The BI tools don't need to hold any customer's PII data; they can instead keep a reference token to that data, along with any customer intelligence data it has gathered.
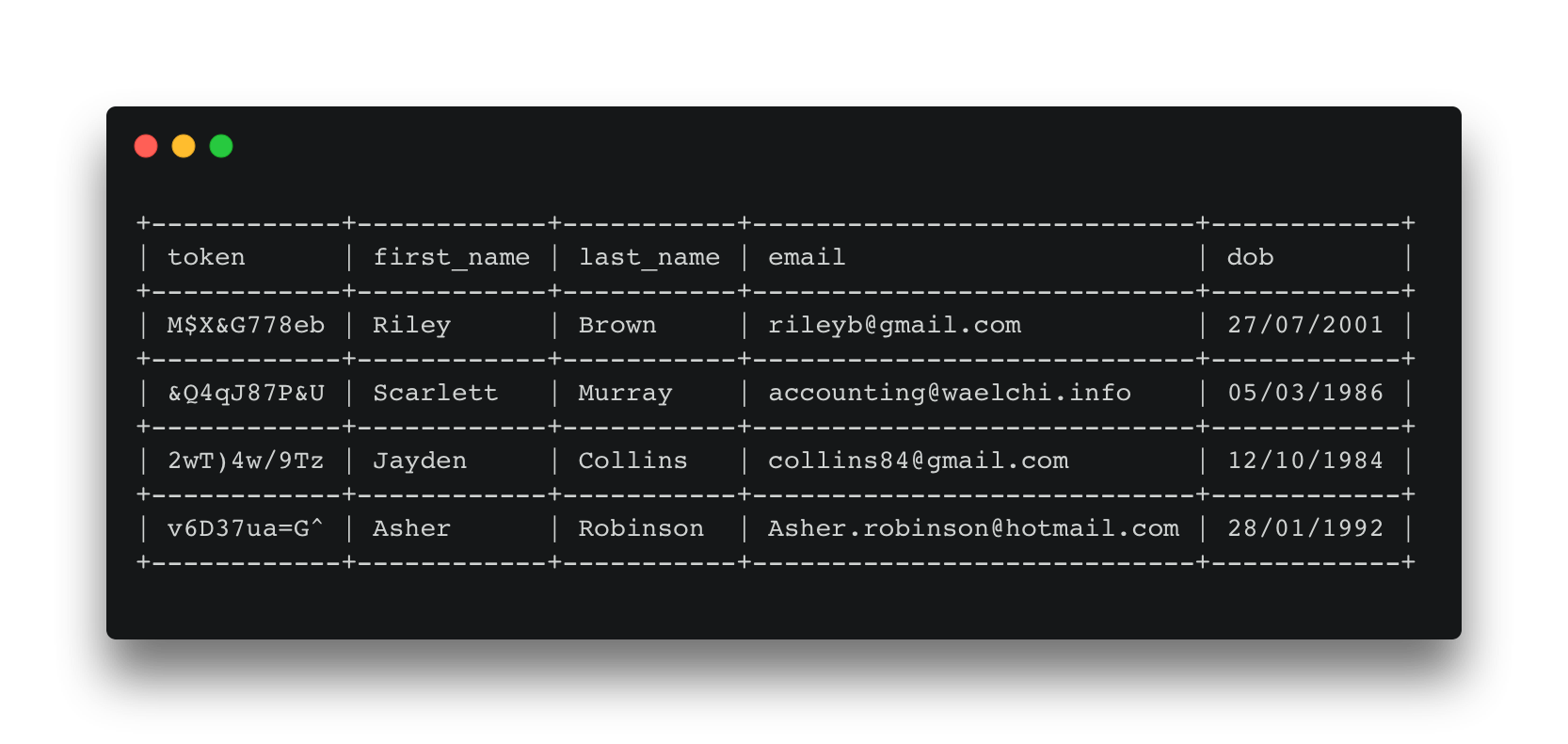
The marketing tools only use the customer's first name and email address when sending an email, so the access level of the marketing tool should be configured only to make this information available. Now we can join the list generated from the BI tool with the customer data from the data vault using the shared token, to produce our marketing campaign list. As th marketing tool only has permission to view first_name and email, this is all that is returned.
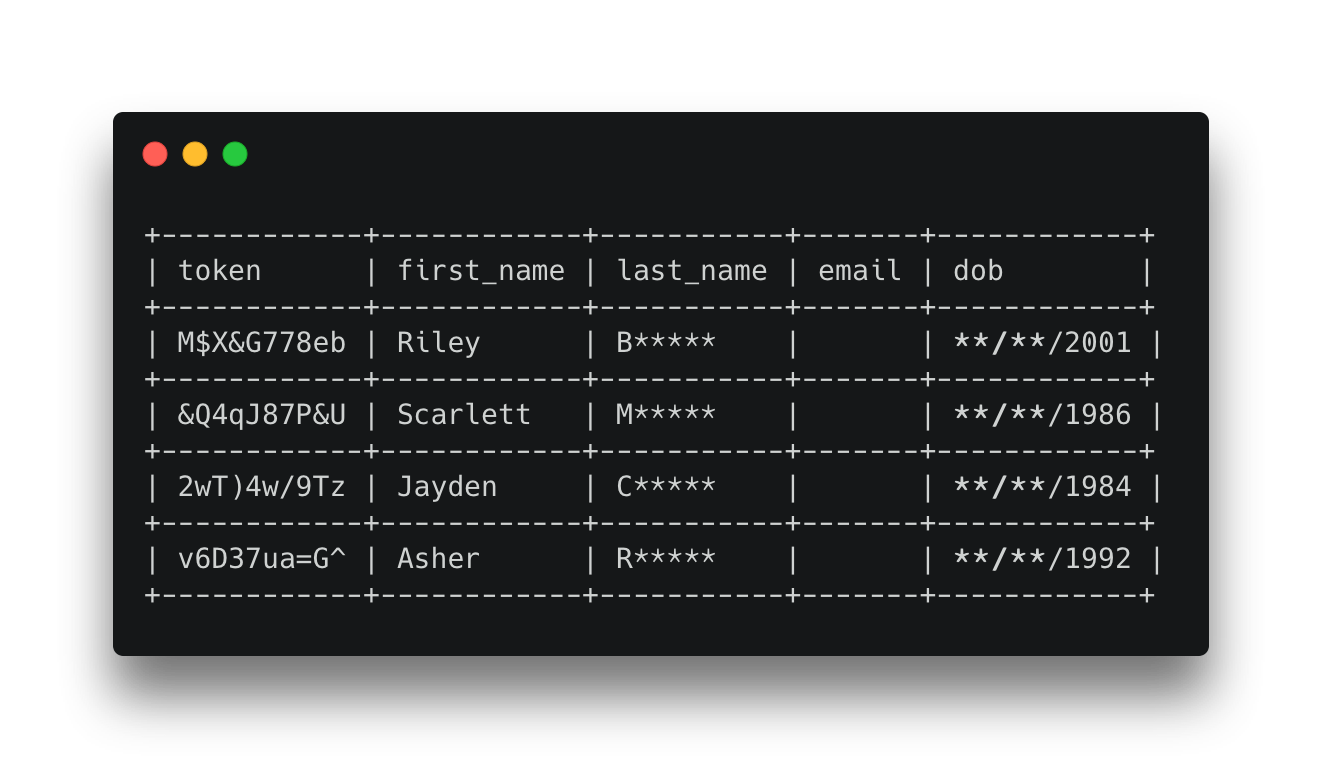
Now suppose we have a customer service application that requires agents to verify a customer's first_name, first letter of last_name and year of birth. This means email is not required and we only need part of the last_name and dob for the workflows, so the only part of the last_name field that needs to be visible is the first letter and the only part of the dob field is the year, the rest can be redacted.
Auditing
When data is spread across multiple locations, it can be challenging to track and manage who has access to the data, what data is being accessed, and how the data is being used.
By centralising data in a single location, the ability to track access and review access levels is greatly simplified as a single access log can be produced.
Implementing a single log for PII access allows for real-time log monitoring solutions to be implemented, which in turn provides timely detection and response to security incidents, such as unauthorised access attempts, spikes in query levels or suspicious activity. Reviewing these logs helps to identify and respond to potential security threats or breaches.
Regular review and audit of these logs should be conducted, and access levels should be updated to reflect workflow and system requirements changes.
Additionally, reviewing access levels helps ensure that the right people have access to the correct data. This helps to limit the exposure risk and ensure that data is protected and used appropriately.
Data Deletion
Modern data-driven businesses typically have a culture of retaining all data, regardless of its relevance or usefulness, fearing the consequences of deleting data that might later turn out to be required or valuable.
Retaining unnecessary PII data increases the exposure risk of a data breach, and there may be legal or regulatory requirements that dictate how long certain types of data must or can be kept.
Centralising PII records helps provide accurate information about when particular PII records have last been accessed, allowing for better deletion strategies that can be better informed about data relevance and usefulness. Having data centralised also means that securely deleting PII data when it is no longer needed is much simpler, and greater assurance can be had that the data has been removed in its entirety.
Challenges
The major challenge with utilising a PII data vault as part of a broader security strategy is the lack of a common standard like that of PCI DSS.
Without common standards, different systems and applications may not be able to communicate with each other or the PII data vault effectively or at all. This can result in inefficiencies and increased integration costs, forcing some level of data spread and replication to allow critical business workflows to continue.
In addition, many cloud-based tools and services rely on data living within their own environment in order to be able to perform their functions. This may be required to perform some proprietary level of data processing or the need to live close to the data to perform critical tasks at high volumes and speeds necessary to deliver their services.
Until there are better standards for PII data valuing, the usefulness of this strategy is limited outside of environments where you control how users, applications and services are accessing the PII data.
{kind=link}